森田ゼミNews Letter No.51


Morita Lab.







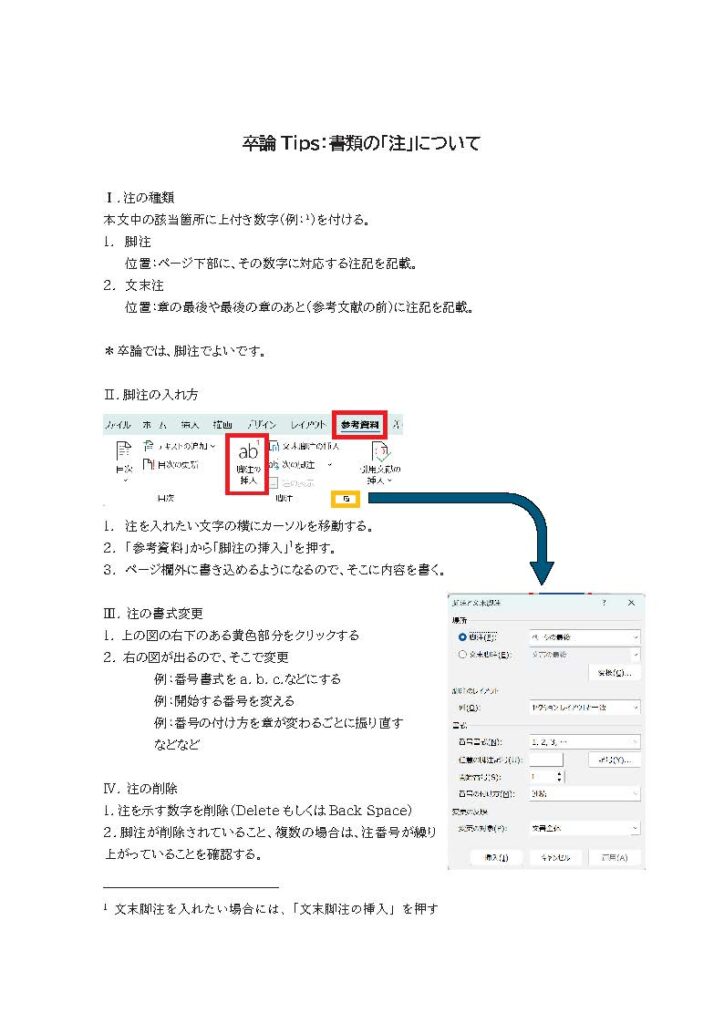
2024年は振り返りを書かなかったので、1年あけての振り返り。
とはいえ、今回振り返るのは2025年のみです。
今年最も大きかったのは、大学運営に関わる立場の変化でした。副理事(教育推進担当)を拝命し、共通教育の運営に携わることになりました。主な仕事は、来年度以降の英語教育のあり方に向けた準備です。
12月末時点では未定な点も残っていますが、大枠が固まったのは一つの前進でした。これで三つ目の大学ですが、いずれも「英語教育の見直し」に関わっているのは、もはや宿命でしょうか。ぐっと涙をこらえるしかありません。
大学教育全体についても、次年度以降、段階的に改善を計画し、実施していくことになるはずです。できることを一つずつ。やるしかありません。
研究面では、ちょうど1年前(2024年12月末)に投稿した論文が、6月に Reading in a Foreign Language に掲載されたことが最大の成果でした。加えて、3年ほど前に公開されたアルファベット文字指導に関する論文がJ-STAGEで公開されたのも、素直に嬉しい出来事です。
また、「『好き』の向こう側」というタイトルの論文が出版されたことも印象深い一年でした。より多くの方に読んでいただければ、なお嬉しいです。
発表は国内2件、国外1件。国内の2件のうち1件は現在投稿準備中なので、どこかで日の目を見てほしいところです。国外の発表は科研の成果の一部で、論文化はまだ先ですが、発表後のコメントが非常に励みになり、研究へのモチベーションが大いに高まりました。
来年早々には共編著の書籍が出版予定なので、まずはそれをきちんと世に出すことが、関わってくださった方々への恩返しになると思っています。
教育面では、着任4年目にして卒論指導8人という、なかなかのカオス状態。12月31日現在も、絶賛卒論添削中です。さて、全員間に合うのでしょうか。
今年の学びは、「卒論指導は8人が限界」ということ。これ以上は正直厳しい。クオリティのコントロールができません。
また、今年はAIをどう使ってもらうかを本格的に考え始めた一年でもありました。卒論に限らず、レポートにもAIの影が見え隠れします。口頭では使い方を指示しているものの、「思考すること」そのものをAIに委ねてしまう学生は、どうしても出てきます。
思考を伴わない文章は、添削してフィードバックを返しても、「何をどう改善すればよいのか」が本人には見えません。これは今後も続く、大きな課題です。さて、どうしたものか。
今年最大の個人的な出来事は、26年ぶりに母校・Northern Arizona Universityを訪れたことでした。国外学会の会場がNAUだったことによるものですが、実に感慨深い夏でした。
お世話になった先生方や先輩、同級生に再会できただけでなく、研究の延長線上で彼らと再び会えたことが、何より嬉しかったです。
来年は科研を着実に進めつつ、新しいプロジェクトも考えていきたいと思います。教育と研究は車の両輪。どちらかに偏りすぎることなく、バランスよく続けていくことを目標にします。
荒瀬科研・内田科研・森田科研共済の第2回 語彙・コロケーション研究会を2025年12月20日・21日に広島市立大学サテライトキャンパスにて開催します。対面のみの開催です。また,会場の都合で先着20名までの受付とさせていただきます。
プログラムが決定しました。ダウンロードは第2回プログラムから!
懇親会を予定しています(6000円程度)。ご参加希望の方は、以下のフォームにて参加登録とともに11月30日までにお知らせください(懇親会キャンセルの場合、不参加でも会費をお支払いいただくことがあります)。
ご質問やキャンセルのご連絡は,morita(a)hiroshima-cu.ac.jpまでお願いいたします((a)は@に変更してください)




