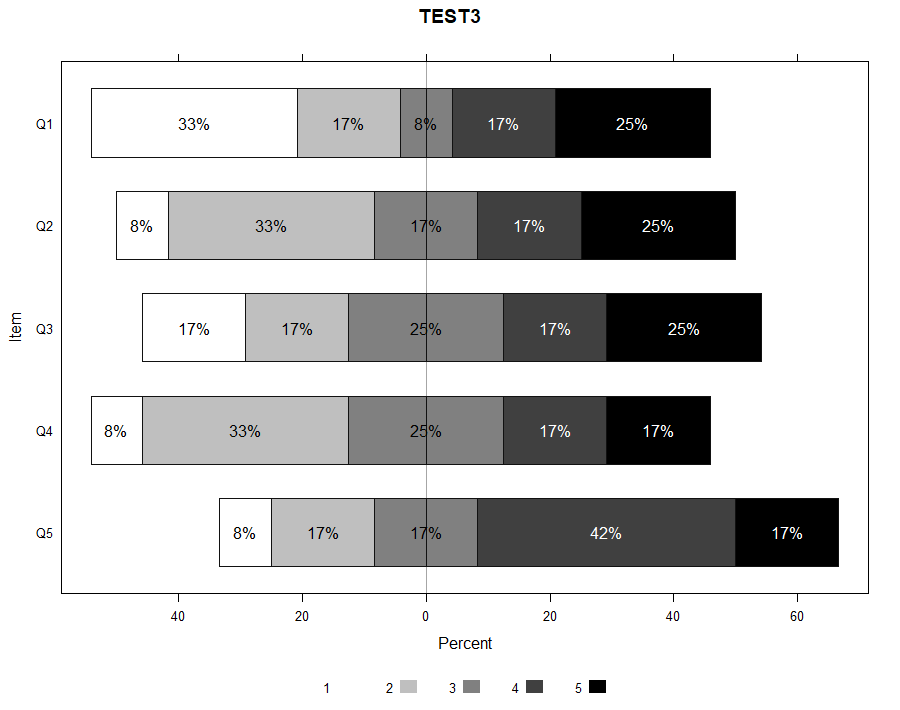
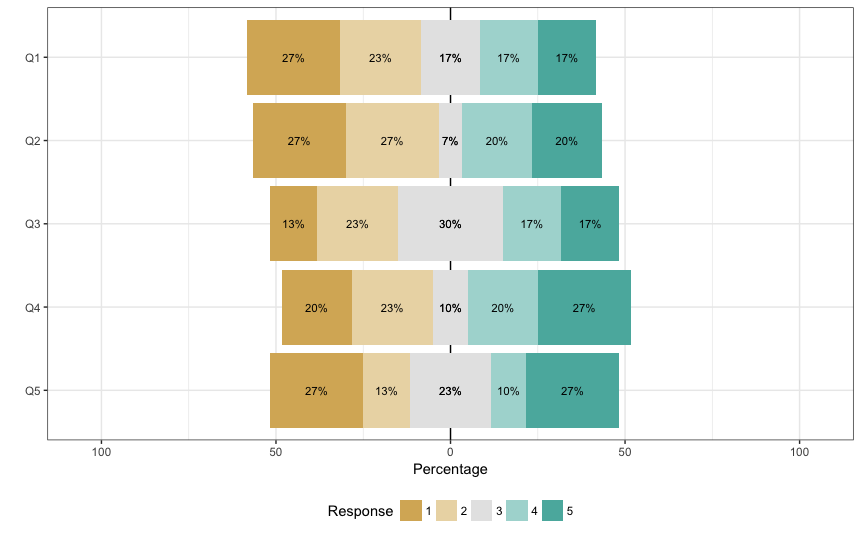
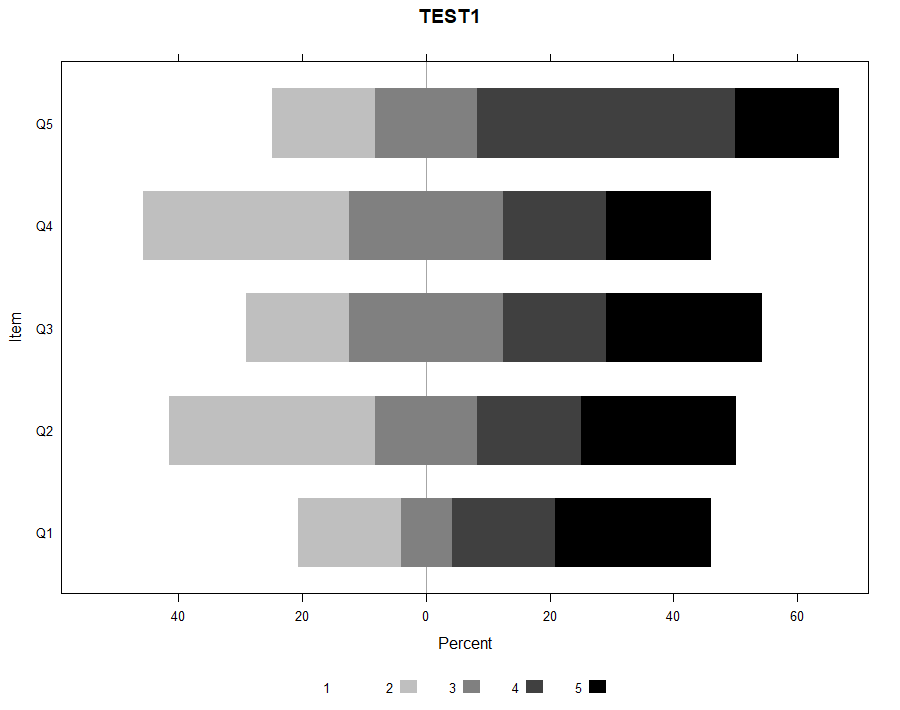
以前のブログ記事で,likert packageを使った視覚化について書いたけれど,今度はHH packageも使う方法。データとしては以前と同じ,以下のイメージ。質問項目は,Q1からQ5まであって,例えば,1が「全く良くない」で,5が「とても良い」のような5件法だとする。データのcsvはこちら。
library(HH)
library(likert)
library(plyr)
dat=read.csv("likert_test.csv", header= T) #データの読み込み
dat2=data.frame(lapply(dat, factor, levels=1:5))
#datの中身をfactor(文字列)に変換。その際に,五件法なので範囲を1から5までとする。つまり,ある設問への反応として1が含まれていない場合などでも,1が0回とするための処置。その上で,データ・フレームにする
HH::plot.likert( #HHでPlotを出す
likert::likert(dat2), #likert packageで集計する
col=rev(grey(seq(0,1,0.25))), #1を白,5を黒,中間がグレーの指定。revをしているので,これを外すと5が黒,1が白。また,1から5段階なので,0.25ずつグラデーションにする。
main ="TEST1" タイトルはTEST1とする
)
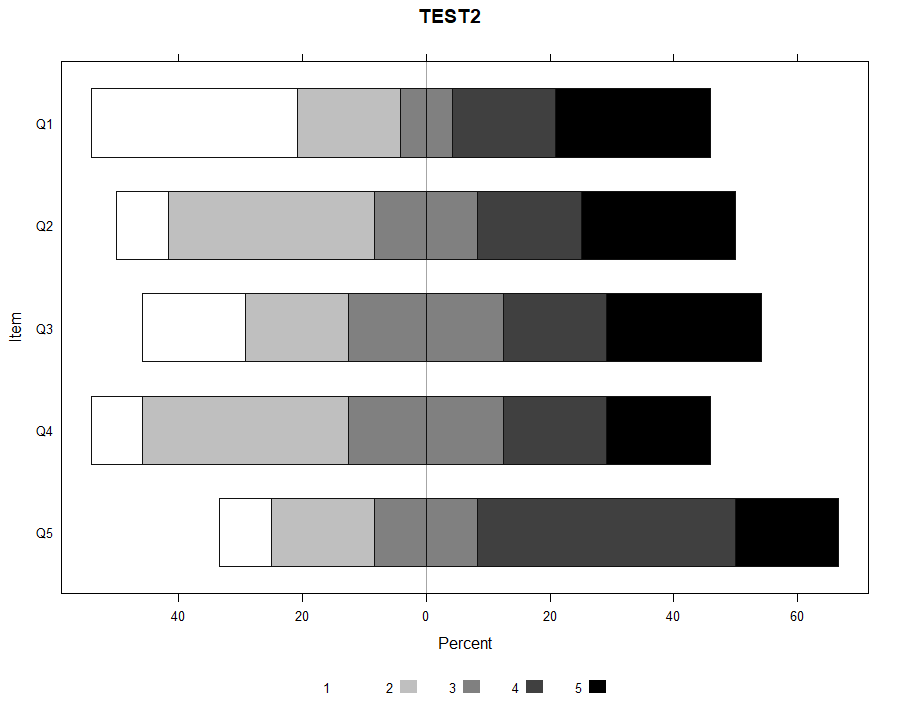
Itemの順番がQ5からQ1になっているのが気になるのと,1が白字なので,枠線がないと見えない。これらを解消。
HH::plot.likert(
likert::likert(dat2),
col=rev(grey(seq(0,1,0.25))),
main ="TEST2",
reverse=F, #Itemの順番を上からQ1の順に
border = c("#111111", "#111111", "#111111", "#111111", "#111111") #グラフの周りを黒枠で囲む
)
グラフの中に%で数値を入れたい。
以下のFunctionはStakFlowのこちらの答えから引用し,変更したもの。グラフ内に数値%を表示する。
myPanelFunc = function(...){
panel.likert(...)
vals <- list(...)
DF <- data.frame(x=vals$x, y=vals$y, groups=vals$groups)
### some convoluted calculations here...
grps <- as.character(DF$groups)
for(i in 1:length(origNames)){
grps <- sub(paste0('^',origNames[i]),i,grps)
}
DF <- DF[order(DF$y,grps),]
DF$correctX <- ave(DF$x,DF$y,FUN=function(x){
x[x < 0] <- rev(cumsum(rev(x[x < 0]))) - x[x < 0]/2
x[x > 0] <- cumsum(x[x > 0]) - x[x > 0]/2
return(x)
})
subs <- sub(' Positive
,'',DF$groups)
collapse <- subs[-1] == subs[-length(subs)] & DF$y[-1] == DF$y[-length(DF$y)]
DF$abs <- abs(DF$x)
DF$abs[c(collapse,FALSE)] <- DF$abs[c(collapse,FALSE)] + DF$abs[c(FALSE,collapse)] DF$correctX[c(collapse,FALSE)] <- 0 DF <- DF[c(TRUE,!collapse),] DF$perc <- round(ave(DF$abs,DF$y,FUN=function(x){x/sum(x) * 100}))
###
panel.text(x=DF$correctX, y=DF$y, label=paste0(DF$perc,'%'), cex=1.0,col=c("black","black","black","white","white")) } #ここは数値と%の表示色を決める。今回は白字とグレーと黒なので,それに合わせて変更している。
以下がPackageを使用したスクリプト
origNames=rownames(dat) #Functionで使うデータの定義
HH::plot.likert(
likert::likert(dat2),
col=rev(grey(seq(0,1,0.25))),
main ="TEST3",
reverse=F,
border = c("#111111", "#111111", "#111111", "#111111", "#111111"),
panel =myPanelFunc #上で定義したFunctionを使う。
)