森田ゼミNews Letter No.6


Morita Lab.






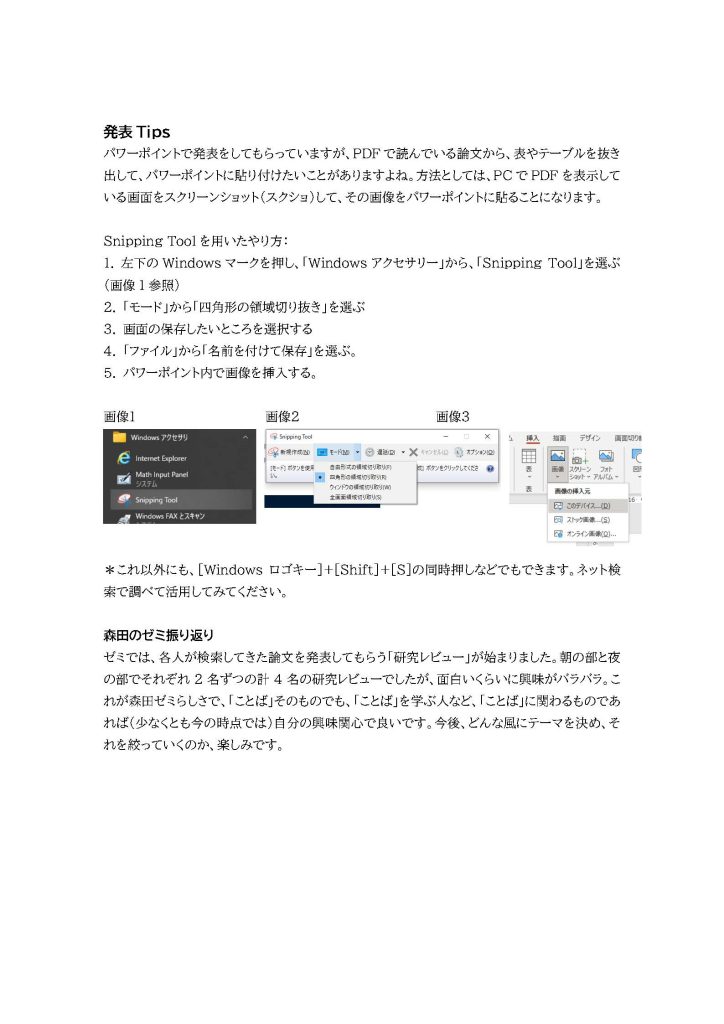



まずは教育面から。異動して2年目ということで、専門の授業の精度を高めたいところだったが、新たな授業やその他の業務で疎かになった。やはり、新たな科目が入るとなかなかに難しい。その科目に時間と労力を振り分けざるを得ないために、昨年度からの授業の見直しが中途半端になってしまう。次年度以降は、しばらくは科目が増えることはないので、既存の授業を見直すかなと。
ちなみに、新規の授業は、後期の「言語コミュニケーション研究入門B」であり、1年生のまだプログラム(=専門)が決まっていない学生向けに、プログラムで何ができるかを知ってもらうための授業。ターム(8回の授業)のうち、4回を担当して、言語、コミュニケーション、異文化、そして言語学習と繋げて話をした。数年後にまた回ってくる科目なので、その時にまた見直そう(とかやっていると、またバタバタと準備しそうだが)。
研究面では、科研も最終年度ということで、これまでの科研の締めくくりで2本の学会発表を行なった。これからの研究用に1本の学会発表。そして、科研ではない研究で面白いと思っていた研究をまとめるために、2本の学会発表をした。この最後の2本はバーミンガム大学で行われたEuroSLAでの発表。しばらくぶりの海外で、対面の英語発表だったが、ただただ楽しかった。ちゃんと論文にしなければ、と言いつつ、5本も発表すると、どれから論文としてまとめるかが悩ましい。
筆頭として論文としての刊行はゼロの年。これは夏に学会発表を集中させすぎて、その準備に時間が取られて論文を書く時間がなかったため。来年度に向けて、そろそろ書き始めよう。ただし、論文としてはゼロだが、最後の最後で大修館の「英語教育」誌に記事を載せたのがせめてもの救いか。2ページで書ききれないことがたくさんあったので、まずはその書ききれなかった部分を中心に論文にしようか。
招待された講演は1本で、母校の名古屋大学で恩師の前で60分間のトーク。EuroSLAの2つの発表を組み合わせて、別の視点で考えたものをまとめた。私らしくない内容と言えな内容だったけれど、研究の進め方やアンケートの結果の解釈などを絡めて、問題提起ができたのでよかったかな。オーディエンスに何かしらのざわざわ感が生まれたのが収穫。
というわけど、学会発表が主だった1年間だったので、来年度は2本くらいは論文を出したいな。そのためには、年明けから準備をしましょう。
以下の論文のTable 5.及びAppendix Bに誤りがありましたので、訂正いたします。この訂正は、全国英語教育学会の事務局及び編集委員会にてご議論いただき、筆頭著者である森田のサイトに掲載する許可を得ています。また、ご指摘いただいた方にもこの場を借りてお礼申し上げます。
対象論文:Morita, M., Uchida, S., and Takahashi, Y. (2021). The frequency of affixes and affixed words in Japanese senior high school English textbooks; A corpus study. ARELE: Annual Review of English Language Education in Japan, 32, 81-95
Laufer, B. (2023). Understanding L2-derived words in context: Is complete receptive morphological knowledge necessary?. Studies in Second Language Acquisition, 1–14. https://doi.org/10.1017/ S0272263123000219
本研究では、テキスト文脈における派生語の理解には、単語部分の完全な理解が必要かどうかを調査する。また、学習者の習熟度と文脈上の手がかりの機能として派生語の理解度を調べた。3つの習熟度レベルの90人の外国語としての英語学習者が、手がかりがない、統語的手がかりがある、統語的手がかりと意味的手がかりがある、という3つの手がかり条件を表す3回の連続テストに参加した。学習者は、非単語ステムと22の頻出接辞(stacement、gummfulなど)で構成される22の派生擬似単語の意味を答えなければならなかった。非語幹の意味は提供された。テストの得点は、3(習熟度)3(手がかり条件)の反復測定による分散分析で比較された。その結果、習熟度と手がかりの両方の変数の効果が示された。理解スコアが最も上昇したのは、統語的手がかりを加えた場合であった。この結果は、学習者の受容的形態素知識が完全でなくても、なじみのある基本語の派生形は理解できることを示唆している。
形態素の指導は第二言語学習者の語彙習得を促進することが証明されている。しかし、接辞の指導が中国語EFL学習者の語彙学習に及ぼす影響に関する研究は比較的少ない。そこで、本研究では、6つの接辞の指導が中国語EFL学習者の語彙学習に与える効果、接辞の指導可能性、および指導に対する学習者の認識について調査することを目的とした。参加者は、台湾南部の中学校の2つの無傷のクラスの中学1年生40名である。1クラス20名を対照群とし、もう1クラス20名を実験群として、6回にわたる接辞のトレーニングを実施した。道具は形態素同定課題、語彙翻訳テスト、生徒の学習日誌、指導に対する認識に関するアンケートであった。その結果、実験グループの接辞の受容的学習に対して、指導がポジティブな効果をもたらすことが示された。また、形態素解析指導に対する生徒の肯定的な認識も示された。本研究は、今後の研究への理論的示唆と接辞の指導に対する教育的示唆を与えて結論とした。