Pavia, N., Webb, S., & Faez, F. (2019). Incidental Vocabulary Learning Through Listening To Songs. Studies in Second Language Acquisition, 41, 1–24. https://doi.org/10.1017/S0272263119000020
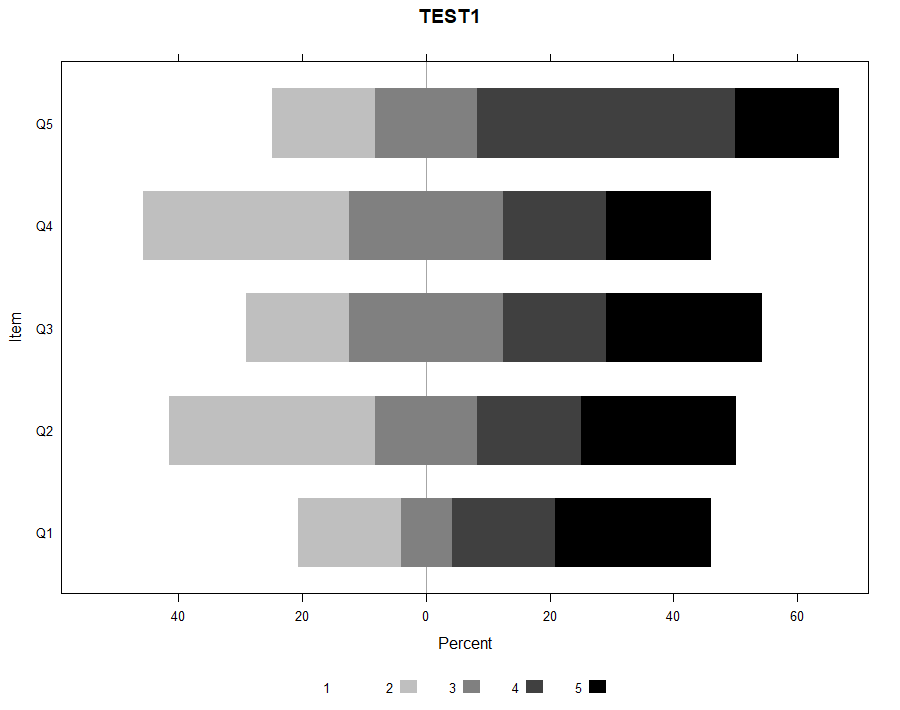
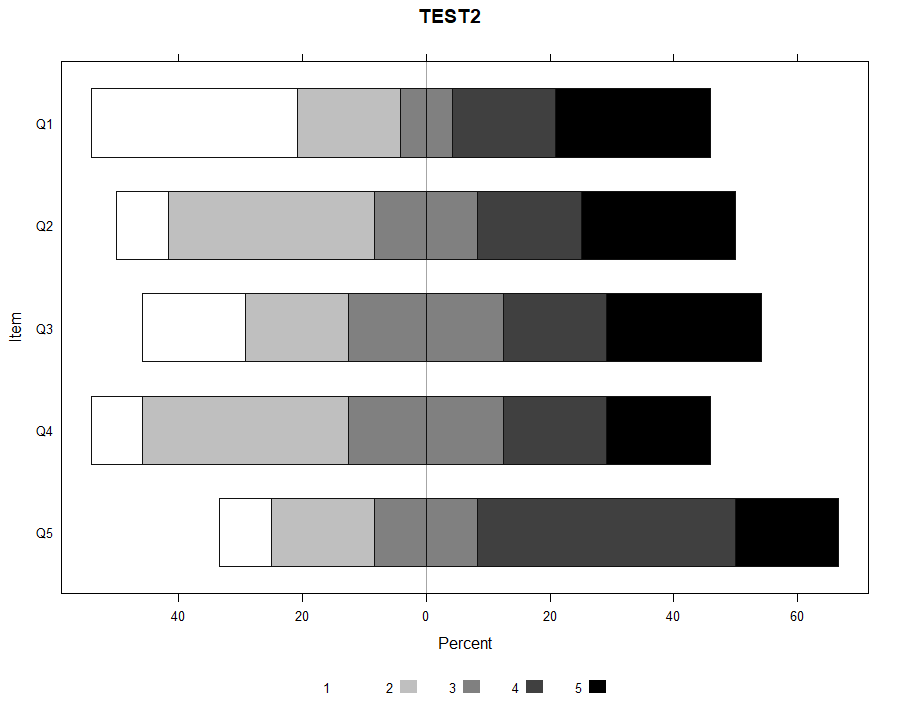
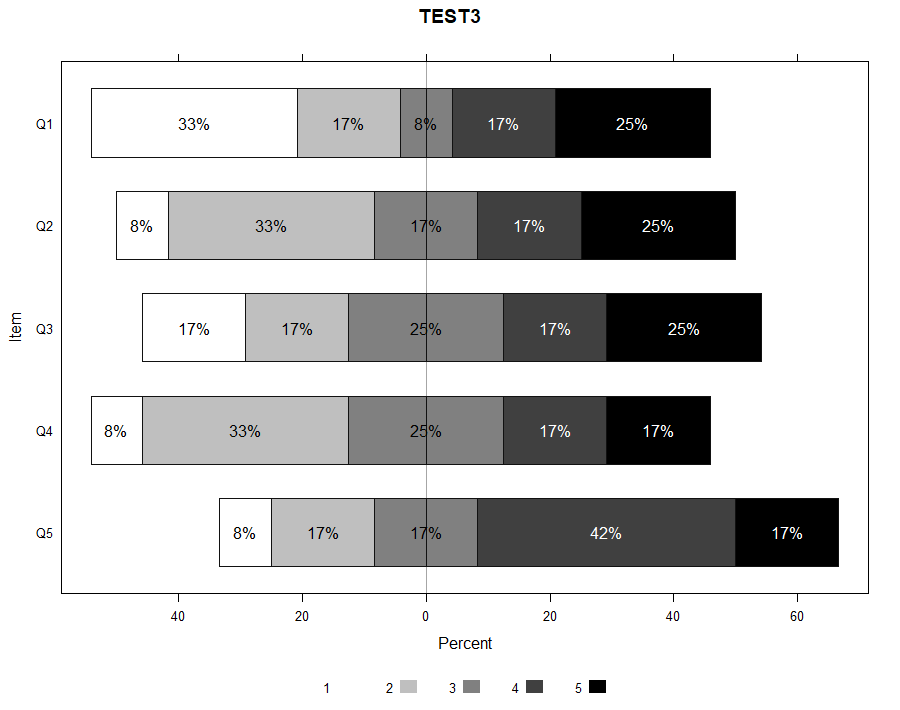
Research investigating incidental vocabulary learning through listening to songs has primarily relied on participant’s self-report surveys on listening behaviors and its relationship with their vocabulary knowledge (Kuppens, 2010). Only one experimental study has investigated vocabulary learning gains from listening to songs (Medina, 1993). From the results, the researcher concluded that learning does occur from listening to songs. However, the learning gains were not provided. The present study investigated incidental learning of three vocabulary knowledge dimensions (spoken-form recognition, form-meaning connection, and collocation recognition) through lis- tening to two songs. The effects of repeated listening to a single song (one, three, or five times) and the relationship between frequency of exposure to the targeted vocabulary items and learning gains were also explored. The results indicated that (a) listening to songs contributed to vocabulary learning, (b) repeated listening had a positive effect on vocabulary gains, and (c) frequency of exposure positively affected learning gains. INTRODUCTION